안녕하세요 :) Cross Planning 본부 이현정입니다.
2025년 7월 5주차 뉴스레터 발송드립니다.📮
<GIANTSTEP News> 빠른 제보는 슬랙 메시지 💌 @XP 사업기획팀 이현정
(📢 매주 목요일 오전까지 접수, 이후 제보는 차주 발행) |
|
|
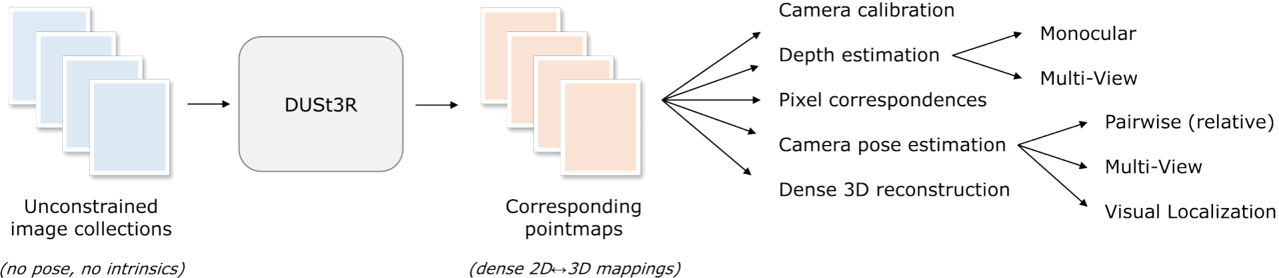
✨ DUSt3R: 카메라 정보 없이도 가능한 3D 재구성
(플랫폼실 AI팀 기고) |
|
|
최근 AI는 2D 이미지를 넘어 3D 공간까지 확장되며, 영화, VFX, 디지털 휴먼 등 다양한 분야에서 핵심 기술로 떠오르고 있습니다. 그중에서도 이미지로부터 3차원 구조를 복원하는 문제는 컴퓨터 비전의 오랜 도전 과제입니다. 이 과정에서 가장 까다로운 단계는 바로 카메라 파라미터의 추정입니다. 이는 3D 공간의 한 점이 이미지 위에 어떻게 투영되는지를 결정하는 핵심 요소지만, 정확히 추정하는 것이 매우 어렵고 까다롭습니다.
이러한 한계를 해결하기 위해 NAVER LABS Europe은 카메라 파라미터 정보 없이도 3D 재구성이 가능한 혁신적인 방법, DUSt3R를 제안했습니다.
🧠 DUSt3R는 어떤 연구인가요? |
|
|
DUSt3R는 최소 두 장의 이미지만으로 3D 장면을 복원하는 모델입니다. 기존 방식들은 깊이 복원 문제를 직접적으로 해결하려 했던 반면, DUSt3R는 이를 포인트맵 회귀 문제로 변환하여 접근합니다. 여기서 포인트맵이란 이미지의 각 픽셀을 실제 3D 공간의 점과 연결하는 일대일 매핑을 의미합니다. 이 포인트맵을 기반으로 깊이 추정, 카메라 파라미터 추정, 3D 복원 등 다양한 작업을 수행할 수 있어, All-in-One 형태의 새로운 패러다임으로 주목받고 있습니다. 또한, 세 장 이상의 이미지가 주어질 경우엔 각 이미지를 한 공간으로 정렬하는 정합 최적화 프로세스도 함께 제안됩니다.
📈 성능은 어떨까요?
DUSt3R는 카메라 정보 없이 단 두 장의 이미지로도 정확한 3D 재구성을 수행하며, 다양한 3D 비전 태스크에서 State-of-the-Art 성능을 입증했습니다. |
|
|
특히 Monocular 및 다중 뷰 깊이 추정, 다중 뷰 카메라 포즈 추정 등 주요 벤치마크에서 탁월한 성과를 보였습니다. |
|
|
🌱 새로운 3D 비전 생태계의 출발점
DUSt3R는 단일 모델을 넘어 하나의 플랫폼으로 확장되고 있습니다. 최근에는 MASt3R-SfM, Fast3R, MUSt3R와 같은 후속 연구들이 DUSt3R를 기반으로 3R 시리즈를 이어가며, 다양한 3D 비전 문제를 아우르는 새로운 흐름을 만들어가고 있습니다. 복잡했던 3D 비전 기술이 더 쉽게, 더 넓게 적용될 시대가 열리고 있습니다.
📄 논문 링크 : https://arxiv.org/abs/2312.14132
🔗 프로젝트 링크: NAVER LABS Europe – DUSt3R |
|
|
📢 AI 기술에 대해 궁금한 점이 있으신 분들은 플랫폼실 AI팀으로 문의주시면
언제든 상담이 가능합니다. 💡 |
|
|
🎬 넷플릭스, AI 기반 VFX 도입… 콘텐츠 제작 속도·비용 모두 잡는다
넷플릭스가 아르헨티나 SF 시리즈 <El Eternauta>에 생성형 AI 기반 시각효과(VFX)를 공식적으로 도입했습니다. 테드 사랜도스 공동 CEO는 “기존보다 10배 빠른 제작 속도와 비용 효율성을 동시에 확보했다”며, AI가 단순 절감 수단을 넘어 콘텐츠 퀄리티 향상에 기여하는 도구임을 강조했습니다. 넷플릭스는 해당 장면에서 AI 툴을 활용해 부에노스아이레스 건물 붕괴 장면을 생성, 전통적인 워크플로우 대비 제작 속도를 크게 단축시켰습니다. 사랜도스는 “실제 아티스트가 더 나은 툴로 작업하는 것이며, AI가 사람을 대체하는 구조는 아니다”라고 밝혔습니다.
이번 AI 도입 사례는 넷플릭스의 2024년 2분기 실적 발표와 함께 공개되었으며, 회사는 전년 동기 대비 16% 상승한 110억 달러 매출을 기록했습니다. ‘오징어게임 시즌3’의 성과와 광고 수익 증가가 실적을 견인했습니다. [더보기]
|
|
|
📢 구글, 유튜브 쇼츠·포토에 AI 비디오 전진 배치…'비오2' 기반
구글이 유튜브와 구글 포토에 생성형 AI 기반 영상 기능을 도입하며, AI 콘텐츠 제작 도구를 본격적으로 확장하고 있습니다. 유튜브는 쇼츠 크리에이터를 대상으로 사진 기반 AI 동영상 생성 기능과 다양한 효과를 적용할 수 있는 도구를 제공하며, 관련 기능을 통합한 ‘AI 플레이그라운드 허브’도 공개했습니다. 구글 포토에서는 ‘섬세한 움직임’, ‘랜덤 스타일’ 등의 효과로 사진을 짧은 동영상으로 자동 변환할 수 있는 기능이 미국 사용자 대상으로 제공 중이며, 8월부터는 새로운 ‘만들기(Create)’ 탭을 통해 접근성이 강화됩니다. 이 모든 기능은 구글의 비디오 생성 모델 Veo 2를 기반으로 작동하며, 여름 말부터는 Veo 3로 전환될 예정입니다. AI로 생성된 콘텐츠에는 디지털 워터마크 기술 ‘신스아이디(SynthID)’가 적용돼, 진짜 이미지로 오인되는 것을 방지합니다. 유튜브의 AI 영상 기능은 현재 미국, 캐나다, 호주, 뉴질랜드에 우선 적용되고 있으며, 향후 점진적인 확대가 예상됩니다. [더보기]
|
|
|
📢 “채팅으로 오브젝트 추가·삭제, 앵글 변경, 스타일 편집까지”… 런웨이, 비디오 편집 AI ‘알레프’ 공개
AI 비디오 생성 전문기업 런웨이(Runway)가 새로운 멀티태스크 영상 생성·편집 모델 ‘알레프(Aleph)’를 발표했습니다. 이 모델은 하나의 시스템으로 객체 추가·삭제, 장면 각도 변경, 스타일 및 조명 조절 등 다양한 작업을 수행할 수 있는 인컨텍스트(in-context) 기반 통합 편집 솔루션입니다. 기존 AI 영상 도구가 특정 기능에 한정된 것과 달리, 알레프는 포괄적 편집 기능을 단일 모델로 지원해, 비디오 제작의 효율성과 창의성을 크게 향상시킬 것으로 기대됩니다. 알레프는 현재 엔터프라이즈 및 창작 파트너에게 우선 제공되며, 향후 일반 사용자에게도 확대될 예정입니다. 런웨이는 앞서 Gen-4, Act-Two 등 선도적 모델을 선보였으며, 최근에는 라이언스게이트, 트라이베카 페스티벌, Media.Monks 등과의 협업을 통해 콘텐츠 창작 생태계를 적극 확장하고 있습니다. [더보기]
|
|
|
📺 “현대미술과 OLED의 조화”⋯ LG전자, 국현미와 ‘디지털 전시’
LG전자가 국립현대미술관(MMCA)과 손잡고 OLED 기술을 접목한 대규모 미디어아트 전시를 선보입니다. ‘MMCA X LG OLED 시리즈’의 첫 전시로, 미디어 아티스트 추수(TZUSOO)의 신작 《아가몬 대백과: 외부 유출본》이 8월 1일부터 내년 2월 1일까지 국립현대미술관 서울관 ‘서울박스’에서 전시됩니다. 전시는 ‘생명과 욕망, 끊임없는 순환’을 주제로 하며, LG OLED 55형 디스플레이 88대로 구성된 두 개의 대형 스크린 월을 통해 작가의 몰입형 세계관을 구현합니다. LG는 작가와의 긴밀한 협업 아래, OLED의 정밀한 색 표현력과 압도적 화질을 기반으로 전시 기획부터 설계, 설치까지 전 과정에 참여했습니다. 이번 협업은 LG전자가 국립현대미술관과 지난해 체결한 3년간의 파트너십의 일환으로, 매년 한 명의 작가를 선정해 기술과 예술이 융합된 전시를 선보이는 장기 프로젝트입니다. [더보기]
|
|
|
국립현대미술관 서울의 ‘서울박스’에 전시된 미디어 아티스트 추수의 대형 설치 미술 「아가몬 대백과: 외부 유출본」. LG전자 제공 |
|
|
|