안녕하세요 :) Cross Planning 본부 이현정입니다.
2025년 8월 2주차 뉴스레터 발송드립니다.📮
<GIANTSTEP News> 빠른 제보는 슬랙 메시지 💌 @XP 사업기획팀 이현정
(📢 매주 목요일 오전까지 접수, 이후 제보는 차주 발행) |
|
|
💪 Diffusion Transformer: 생성형 모델이 강해진 이유
(플랫폼실 AI팀 기고) |
|
|
🎆 바야흐로 Diffusion DiT의 시대? |
|
|
GAN, VAE, PixelRNN 등 과거부터 이미지와 비디오를 생성하기 위한 다양한 인공지능 모델들이 존재했습니다. 하지만 이러한 모델들은 생성 품질의 한계, 학습의 불안정성, 낮은 확장성 등 여러 제약이 있었습니다.
Diffusion 기법의 발전 이후, 우리는 DALL-E, Imagen, Stable Diffusion부터 최근 공개된 Veo3, Sora에 이르기까지 과거에는 상상하기 어려웠던 수준의 생성 모델들을 경험하고 있습니다. 특히 영상 생성 영역에서도 유튜브 영상, CF, 예능 프로그램 등에서 AI로 생성된 콘텐츠를 자주 접하게 되었죠.
이 눈부신 발전의 이면에는 사실 ChatGPT로 대표되는 대형 언어 모델(LLM)을 탄생시킨Transformer 구조의 도입이 자리하고 있습니다. 오늘은 Diffusion의 한계를 넘어서기 위해 Transformer를 도입한 모델, DiT (Diffusion Transformer) 에 대해 알아보려 합니다. 이 모델은 2022년 논문 "Scalable Diffusion Models with Transformers" 에서 처음 소개되었으며, 이후 많은 최신 모델의 기반(backbone)으로 채택되고 있습니다.
🎨 Diffusion: 생성 모델의 새로운 흐름 |
|
|
Diffusion 모델은 2020년경 본격적으로 부상하기 시작했습니다. 대표적으로 DDPM (Denoising Diffusion Probabilistic Model) 은 이미지에 점진적으로 노이즈를 추가하고, 이를 역방향으로 복원해가는 방식으로 이미지를 생성합니다.
이후 Latent 공간에서 연산을 수행하는 LDM (Latent Diffusion Models) 이 등장하면서 효율성과 해상도가 크게 향상되었습니다. 이를 통해 텍스트-이미지 생성의 대중화가 가능해졌죠 (ex. Stable Diffusion).
하지만 초기의 DDPM, LDM 기반 모델들은 대부분 U-Net 기반 CNN 구조를 사용했습니다. 이는 이미지의 국소적 패턴을 처리하는 데는 적합하지만, 전역적인 구조를 포착하거나 대규모 확장성 측면에서는 한계가 존재했습니다.
🧠 Transformer: 모든 도메인을 넘어 |
|
|
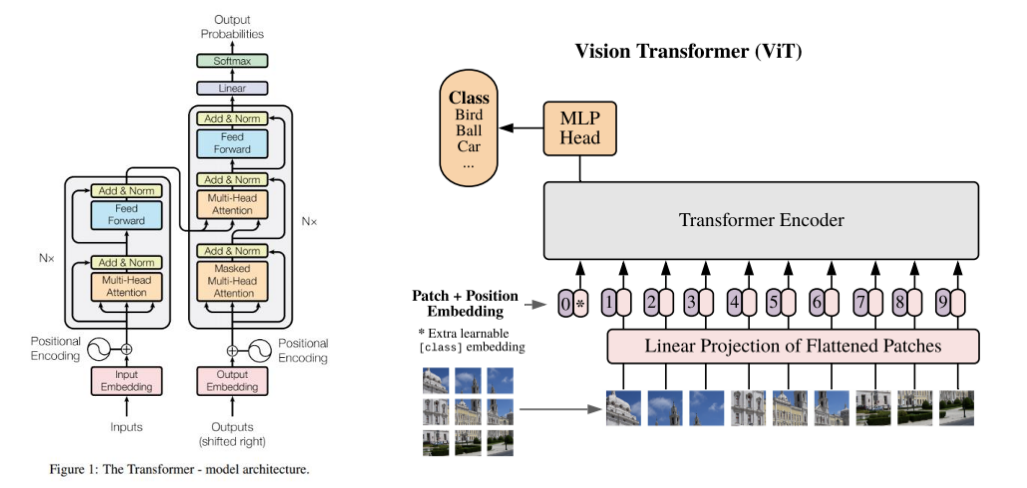
2017년 등장한 논문 Attention is All You Need 이후, Transformer는 NLP를 넘어 Vision, Speech, Multimodal 등 거의 모든 도메인의 핵심 아키텍처로 자리잡았습니다. 언어 분야에서는 BERT, GPT 계열 모델들이 압도적인 성능을 보이며 기존의 RNN, LSTM 기반 모델들을 대체했고,
이미지 분야에서는 ViT (Vision Transformer) 가 CNN을 대체하기 시작하며 대규모 이미지 분류/생성에서 두각을 나타냈습니다.
OpenAI의 Scaling Laws for Neural Language Models 논문에서는 Transformer가 크기(파라미터 수)와 데이터가 증가할수록 안정적으로 성능이 향상된다는 scaling law 를 정량적으로 분석하며 주목받았습니다. 이러한 흐름 속에서 Diffusion 모델의 backbone도 CNN에서 Transformer로 옮겨가는 변화가 자연스럽게 시작된 것입니다. 바로 DiT(Diffusion Transformer)의 등장이 그 분기점입니다. |
|
|
🔄 DiT, Diffusion과 Transformer의 만남 |
|
|
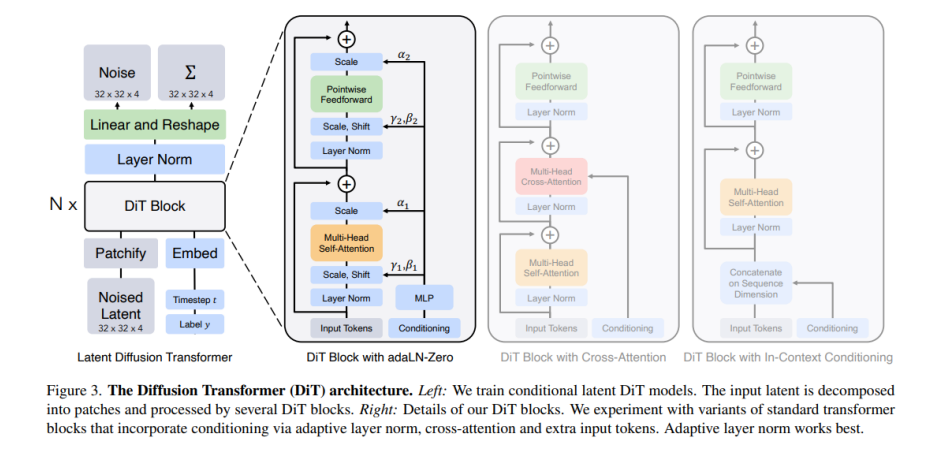
DiT는 ViT의 구조를 기반으로 하면서도, 이를 Diffusion 방식에 맞게 설계한 모델입니다.
- 입력 이미지는 ViT와 마찬가지로 일정 크기의 패치로 나뉘고, 각 패치는 linear projection을 통해 embedding 벡터로 변환됩니다.
- 각 timestep은 time embedding을 통해 positional 정보와 함께 입력에 더해집니다.
- 이 시퀀스는 standard Transformer encoder 블록을 통과하면서 denoising을 위한 특징 추출을 수행합니다.
- 최종적으로 예측된 결과는 reverse diffusion 과정을 통해 이미지를 재구성합니다.
이때 DiT는 기존 U-Net 기반의 Diffusion 모델들과 동일한 조건에서 비교 실험되었으며, FID, IS 등의 지표에서 매우 경쟁력 있는 결과를 보여주었습니다. 무엇보다 DiT는 Transformer 기반 모델답게 scaling property가 뛰어나, 모델 크기(예: DiT-XL/2)와 데이터가 증가할수록 성능이 꾸준히 향상됨을 실험적으로 증명했습니다. |
|
|
최근 발표된 Sora(OpenAI), Veo3(Google), Hunyuan3D(Tencent) 등, 대부분의 초대규모 영상생성 모델은 DiT를 backbone으로 채택하고 있습니다. 이는 단순한 트렌드가 아니라, "확장성 있는 구조 + 고품질 생성 + 멀티모달 통합" 이라는 세 가지 요건을 만족시키는 유일한 해답이기 때문입니다. 이미지, 비디오 생성 AI의 전성기는 이제부터 시작입니다. 그리고 그 중심엔 Transformer 기반의 DiT가 자리하고 있습니다. |
|
|
📢 AI 기술에 대해 궁금한 점이 있으신 분들은 플랫폼실 AI팀으로 문의주시면
언제든 상담이 가능합니다. 💡 |
|
|
🧠 '생각하는 AI' GPT-5 나왔다…"모든 영역 박사급 수준"
오픈AI가 차세대 생성형 AI 모델 ‘GPT-5’를 공개했습니다. GPT-4 이후 2년 만에 선보인 이번 모델은 기본 모델·깊은 추론 모델(GPT-5 Thinking)·질문 복잡도에 따라 모델을 선택하는 라우터로 구성된 통합 시스템을 갖췄습니다. 수학, 코딩, 작문, 의료, 시각 인식 등 전 분야에서 성능이 향상됐으며, 환각과 아첨 성향이 크게 줄었습니다. 코딩 분야에서는 복잡한 웹·앱·게임을 단일 프롬프트로 제작할 수 있고, 창작 글쓰기와 맞춤형 의료 조언 능력도 강화됐습니다. AIME 94.6%, SWE-bench 74.9%, MMMU 84.2%, GPQA 88.4%(프로 버전) 등 주요 벤치마크에서 최고 기록을 경신했습니다. 안전성 측면에서는 사실 오류 가능성을 최대 80% 낮추고, 민감 분야에는 ‘안전 완성’ 훈련법을 도입했습니다. GPT-5 프로는 사용자 맞춤형 성격 4종과 향상된 반응 정확도를 제공하며, 더 깊은 추론으로 종합성과 정확성을 높였습니다. 샘 알트먼 CEO는 “GPT-5는 박사급 전문가와 대화하는 느낌”이라고 평가했습니다. [더보기]
|
|
|
📢 구글 딥마인드, 인간 수준 AI에 한걸음…'지니3'으로 현실감 극대화
구글 딥마인드가 범용 인공지능(AGI) 개발의 핵심 기술로 평가되는 차세대 세계 모델 ‘지니3(Genie 3)’를 발표했습니다. 지니3은 단순 그래픽 생성에 그치지 않고, 물리 법칙을 이해하고 이를 기억하는 기능을 갖춰 보다 현실적인 시뮬레이션 환경을 제공합니다. 사용자는 텍스트 프롬프트만으로 720p 해상도의 상호작용형 3D 환경을 생성할 수 있으며, AI는 이 환경 안에서 자유롭게 탐색하고 학습할 수 있습니다.
이번 모델은 딥마인드의 확장 가능 학습형 다중 세계 에이전트(SIMA)와 연동돼, AI가 주어진 목표를 스스로 계획·탐색하며 수행하는 과정을 지속적으로 시뮬레이션합니다. 예를 들어, 창고 환경에서 특정 물건을 찾아내는 미션이 주어지면, 지니3은 해당 상황을 반복적으로 재현하며 학습 효율을 높입니다.
다만, 아직은 복잡한 물리적 상호작용을 완벽히 구현하지 못하고, 상호작용 가능 시간도 수 분 내외로 제한되는 등 기술적 한계가 존재합니다. 연구팀은 이러한 부분을 개선하기 위한 개발을 이어가고 있으며, 그럼에도 지니3은 AI가 자율적으로 학습할 수 있는 기반을 제공함으로써 AGI 실현에 한 걸음 더 다가섰다는 평가를 받고 있습니다. [더보기]
|
|
|
📢 일론 머스크 xAI '그록 이메진' 전면 무료화…오픈AI 견제 맞불
xAI가 AI 이미지-영상 변환 도구 ‘그록 이메진(Grok Imagine)’을 전면 무료로 개방했습니다. 이 도구는 사용자가 직접 생성하거나 업로드한 이미지를 버튼 한 번으로 짧은 동영상으로 변환할 수 있으며, iOS와 안드로이드용 그록 앱에서 이용 가능합니다. 현재 무료로 제공되는 이미지-영상 변환 AI 도구가 드문 만큼, 복잡한 편집 과정 없이 간편하게 콘텐츠를 제작할 수 있다는 점에서 크리에이터와 일반 사용자 모두의 관심을 받고 있습니다. GPT-5 출시로 경쟁이 치열해지는 가운데, xAI의 무료 개방 전략이 AI 영상 생성 시장 판도에 어떤 영향을 미칠지 주목됩니다. [더보기] |
|
|
|