안녕하세요 :) Cross Planning 본부 이현정입니다.
2025년 4월 4주차 뉴스레터 발송드립니다.📮
<GIANTSTEP News> 빠른 제보는 슬랙 메시지 💌 @XP 사업기획팀 이현정
(📢 매주 목요일 오전까지 접수, 이후 제보는 차주 발행) |
|
|
MoCha: 말과 텍스트로 영화 수준의 캐릭터 애니메이션 생성하기
(플랫폼실 AI팀 기고) |
|
|
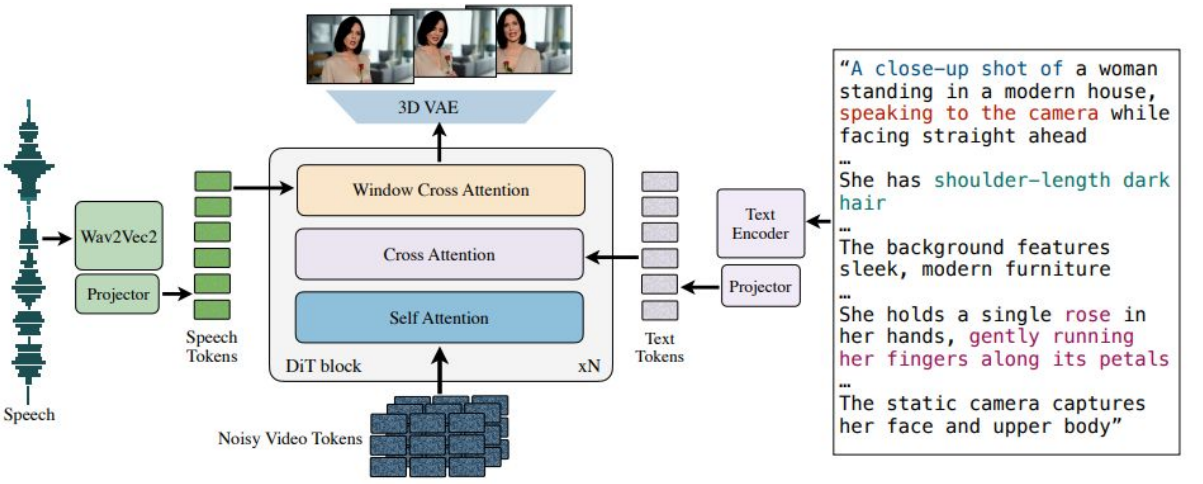
🎬✨ MoCha: 영화 같은 AI 캐릭터 합성 영상 생성 모델
SoRA, Pika, Luma 등, 텍스트 프롬프트만으로 실제 영상과 동일한 수준의 장면을 만들어내는 것도 가능한 시대가 되었습니다. 하지만 이런 모델들은 여전히 ‘말하는 캐릭터’를 자연스럽게 표현하는 데는 한계를 가지고 있습니다. 입 모양이 어색하거나, 표정이 없거나, 말은 하지만 몸은 가만히 있는 모습이 바로 그 한계입니다. 이 문제를 해결하기 위해 등장한 것이 바로 MoCha입니다.
🗣️ MoCha는 어떤 모델인가?
MoCha는 음성(Speech)과 텍스트(Text)를 기반으로 진짜 사람처럼 말하고 움직이는 캐릭터를 생성하는 AI 모델입니다. 단순히 얼굴만 움직이는 ‘Talking-head’ 수준을 넘어서, 전신 모션, 표정 변화, 심지어는 여러 명의 캐릭터 간 대화까지 생성할 수 있습니다.
🔍 MoCha가 특별한 이유
|
|
|
✅ 보조 정보 없이 훈련
기존 모델들은 참조 이미지나 키포인트 같은 부가 정보에 의존했지만, MoCha는 텍스트와 음성만으로 학습됩니다.
✅ 말과 입모양 싱크를 위한 어텐션 메커니즘
기존 방식은 말소리에 맞춰 입을 움직이기 어려웠는데, MoCha는 짧은 오디오 조각을 기준으로 입 모양과 정확하게 맞물리는 프레임을 생성합니다.
✅ 다수의 캐릭터 대화도 문제 없음
MoCha는 여러 명의 캐릭터가 번갈아 가며 말하고 반응하는 영상도 생성할 수 있습니다. 실제 인터뷰 영상처럼 보이기도 하죠.
✅ 텍스트 기반 자유도 높은 제어
"빨간 옷을 입은 소녀가 앞을 보고 말한다" 같은 문장 하나만으로 캐릭터의 모습과 위치까지 제어할 수 있습니다.
🎥 결과물은 어떨까?
MoCha가 생성한 영상은 다음과 같은 기준에서 평가됩니다:
- 🎤 입 모양 싱크 – 말소리와 입 움직임의 일치도
- 😊 표정 자연스러움 – 감정 표현의 풍부함
- 🕺 몸짓 유창함 – 전신 모션의 부드러움
- 🧾 프롬프트 일치도 – 설명한 내용과 장면이 일치하는가
- 🎨 비주얼 퀄리티 – 영상 자체의 품질
🧪 MoCha는 이렇게 학습됐습니다!
- 총 300시간, 50만 개 이상의 영상 샘플 사용
- 오디오 기반 학습(Speech-to-Video)과 텍스트 기반 학습(Text-to-Video)을 혼합해서 다양성과 정밀도를 동시에 확보
- 대사, 감정, 위치, 외형 등을 LLM(LLaMA3) 기반으로 자동 캡셔닝하여 훈련
🧙 결과 영상 보기
💡 MoCha는 단순히 비디오를 ‘그럴듯하게’ 만드는 걸 넘어서, 캐릭터의 생각, 감정, 말투까지 표현하는 새로운 차원의 영상 생성 AI입니다.
➡️ 실제 영상 보기 https://congwei1230.github.io/MoCha/ |
|
|
📢 AI 기술에 대해 궁금한 점이 있으신 분들은 플랫폼실 AI팀으로 문의주시면
언제든 상담이 가능합니다. 💡 |
|
|
📢 숏폼·뮤비 '척척'… 창작지형 바꾸는 AI
인공지능(AI)이 콘텐츠 제작 방식을 혁신하며 산업 전반에 큰 변화를 가져오고 있는데요. 대표적인 예시들은 다음과 같습니다.
- 카카오엔터의 '헬릭스 숏츠'
카카오엔터테인먼트가 AI 기반 숏폼 영상 제작 서비스 '헬릭스 숏츠'를 도입 / 웹툰 이미지를 자동으로 컷 분할하고, 대사를 제거한 후, 광학문자인식(OCR) 기술로 줄거리를 요약하여 내레이션 생성 / 웹툰 미리보기 영상 제작 기간이 기존 3주에서 3시간으로 단축 & 비용은 200만 원에서 6만 원 수준으로 감소
-
게임 산업의 AI 활용
크래프톤은 엔비디아의 소규모언어모델(SLM)을 활용하여 유저와 실시간 대화가 가능한 AI 게임 캐릭터를 개발 / 유저와 실시간으로 대화하면서 실제 사람처럼 그에 맞게 반응 / 신작 게임 '인조이'에 본격 적용
이치럼 AI가 미디어 콘텐츠 제작 과정에 깊게 침투하면서 관련 시장도 급성장하고 있습니다. 시장조사기관 글로벌인포메이션에 따르면 미디어 콘텐츠 제작용 AI 시장 규모는 2024년 82억1000만달러(약 11조6000억원)에서 연평균 35.6%씩 성장해 2030년에는 510억8000만달러(약 72조6000억원)에 이를 것으로 예상된다고 합니다. [더보기]
|
|
|
📹 알리바바, 최신 AI 영상 생성 모델 ‘완2.1-FLF2V-14B’ 오픈소스로 공개
알리바바 그룹의 디지털 기술 및 인텔리전스 중추인 알리바바 클라우드가 새로운 인공지능(AI) 영상 생성 모델 ‘Wan2.1-FLF2V-14B’를 23일 오픈소스로 공개했습니다. Wan2.1-FLF2V-14B는 알리바바 클라우드의 파운데이션 모델 시리즈인 '완2.1(Wan2.1)’에 속하며, 텍스트와 이미지 입력을 기반으로 고품질의 이미지와 영상을 생성하는 데 최적화된 모델입니다. 모델은 사용자 명령어의 정밀한 실행은 물론, 첫 프레임과 마지막 프레임 사이의 시각적 일관성을 유지하며, 복잡한 동작을 자연스럽게 연결해 사실적인 영상 결과물을 제공합니다. Wan 시리즈의 공식 웹사이트에서는 해당 모델을 활용해 720p 해상도의 5초 분량 영상을 무료로 생성 가능하다고 하네요. [더보기]
|
|
|
🎬 AI와 수작업의 융합, 스눕 독의 초현실주의 뮤직비디오 공개
탐 페티의 곡 ‘Mary Jane’s Last Dance’를 리메이크한 스눕 독의 신곡 뮤직비디오가 공개되었습니다. Temple Caché가 제작한 이 영상은 AI와 전통적 애니메이션 기법을 융합해 실험적이고 초현실적인 비주얼을 구현했다고 하는데요. 자체 개발한 AI 도구로 창의성을 확장하되, 디테일 표현을 위해 전 장면을 아티스트가 프레임 단위로 수작업 완성한 것이 특징입니다. Temple Caché가 개발한 자체 AI 도구를 포함한 신기술이 잘 활용되었으나, Psyop의 총괄 프로듀서인 앤드류 린스크(Andrew Linsk)는 “이야기를 전달하는 데는 표정에서부터 몸짓까지 섬세한 표현이 필요한데, AI는 아직 이런 디테일을 완전히 구현하지 못합니다. 그래서 장면마다 일관성을 유지하고 미묘한 디테일을 살리기 위해, 모든 프레임은 인간 아티스트의 손으로 다시 그려지고, 합성되며, 수작업으로 레이어 처리되었습니다.”라고 설명했습니다. [더보기] |
|
|
🎪 DDP 최초 레이저 아트 전시…윤제호 ‘이원공명’
서울디자인재단이 오디오 비주얼 아티스트 윤제호의 개인전 ‘이원공명(Resonance of Reality and Virtuality)’을 오는 25일부터 동대문디자인플라자(DDP) 디자인랩에서 개최합니다. 이번 전시는 DDP에서 처음으로 선보이는 레이저 아트 전시로, ‘현실과 가상’, ‘기술과 감각’의 경계를 주제로 한 총 네 개의 존(Zone)으로 구성되어 있습니다. 각 존은 연극의 한 장면처럼 연출되어, 관람객이 자유롭게 이동하며 자신만의 해석으로 작품을 완성해가는 구조입니다. 전시는 추상적인 빛의 흐름에서 출발해, 사운드·설치·영상이 하나의 시퀀스를 이루며 감각적인 내러티브를 만들어냅니다. 서울디자인재단 차강희 대표는 “이번 전시는 기술과 감각이 만나는 오늘날의 미디어아트가 어디까지 확장될 수 있는지를 보여준다”며, “관람자에게 새로운 감각의 창을 여는 계기가 될 것”이라고 전했습니다. [더보기] |
|
|
|