안녕하세요 :) Cross Planning 본부 이현정입니다.
2025년 4월 3주차 뉴스레터 발송드립니다.📮
<GIANTSTEP News> 빠른 제보는 슬랙 메시지 💌 @XP 사업기획팀 이현정
(📢 매주 목요일 오전까지 접수, 이후 제보는 차주 발행) |
|
|
자이언트스텝, 애니메이션 영화 '예수의 생애(King of Kings)' 제작 투자 및 제작 참여 🎥
자이언트스텝이 투자와 제작을 동시에 진행한 애니메이션 영화 '예수의 생애(King of Kings)'가 개봉했다는 소식입니다. 자이언트스텝 미국지사(GIANTSTEP LA)의 이희복 감독님이 타이틀 시퀀스 제작에 참여해 의미를 더한 작품인데요. 이 영화는 영국 작가 찰스 디킨스가 어린 자녀들을 위해 쓴 <우리 주님의 생애>(The Life of Our Lord)를 각색한 작품이며, 할리우드 유명 배우인 오스카 아이작, 피어스 브로스넌, 케니스 브레너, 우마 서먼 등이 캐릭터 더빙을 맡았습니다. '예수의 생애'는 지난 4월 11일 북미 3,200개 극장에서 개봉함과 동시에 사흘 연속(11~13일) 박스오피스 2위에 오르며 돌풍을 일으키고 있습니다. 미국 대중문화매체 버라이어티는 한국에서 제작된 애니메이션의 이 같은 성과를 두고 이변이라고 평가했으며, 실제로 시장조사업체 시네마스코어의 현장 관객 설문조사에서 최고 등급(A+)을 받는 등 현지 반응이 뜨겁다고 하네요. 올 여름 국내 개봉 또한 계획 중에 있다고 하니, 많은 응원을 부탁드립니다! 👏 [더보기]
|
|
|
▶︎ '예수의 생애(King of Kings)' 공식 트레일러 영상 |
|
|
▶︎ '예수의 생애(King of Kings)' 공식 트레일러 영상 크레딧 이미지 (자이언트스텝 기재) |
|
|
AI 기술로 빚는 렌더링 기술의 혁신
(플랫폼실 AI팀 기고) |
|
|
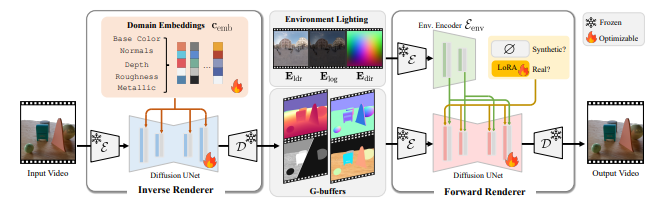
DiffusionRenderer: 영상 기반 물리 렌더링의 새로운 패러다임
이번 뉴스레터에서는 영상 속 빛과 재질을 AI로 자유롭게 조정할 수 있는 NVIDIA의 최신 연구 논문, DiffusionRenderer를 소개드립니다.
이 기술은 영상 생성 AI(VDM)와 전통적인 물리 기반 렌더링(PBR)의 장점을 결합하여 단일 영상만으로도 현실감 있는 재조명(relighting), 재질 변경(material editing), 물체 주입(object injection)이 가능한 새로운 프레임워크입니다.
왜 중요한가요?
현실적인 3D 영상 합성을 위해선 보통 아래와 같은 정보가 필요합니다:
- 물체의 형태(geometry)
- 재질(material)
- 조명 환경(lighting)
하지만 이러한 정보는 실제 영상에는 존재하지 않으며, 수작업으로 추출하기도 어렵습니다.
이 문제를 해결하기 위해 DiffusionRenderer는 영상만 보고도 이러한 정보를 하나의 통합된 프레임워크로 AI가 직접 추정할 수 있도록 학습합니다.
어떻게 작동하나요? |
|
|
1. Inverse Rendering (정보 추정 단계)
영상에서 아래와 같은 장면 속성(G-buffer)을 추정합니다:
- n: 표면 법선 (Normal)
- d: 깊이 정보 (Depth)
- a: 색상 정보 (Albedo)
- r: 거칠기 (Roughness)
- m: 금속성 (Metallic)
이 값들을 통해 각 픽셀의 재질, 위치, 표면의 굴곡 등을 예측합니다. 이 과정에서 OpenAI의 CLIP과 유사한 Cross-Attention 기법으로, 도메인 정보를 잘 인식하도록 돕습니다.
2. Forward Rendering (영상 복원 단계)
앞서 예측된 정보 + 주변 환경 조명 정보를 바탕으로 최종 영상을 재구성합니다.
조명 정보는 다음과 같이 다층적 구조로 인코딩됩니다:
- E_ldr: 밝기 조절된 조명 이미지
- E_log: 고휘도 조명의 비율 보정
- E_dir: 방향성을 반영한 조명 공간
이를 통해 기존 물리 렌더링과 달리 복잡한 그림자, 반사, 조명 효과를 AI가 스스로 이해하고 표현합니다.
어떤 데이터로 학습했나요?
- 초기에는 3D 데이터 기반 합성 데이터(synthetic data) 영상으로 inverse renderer를 학습.
- 이후 이를 바탕으로 실제 영상에서 PBR 정보를 추정하는 pseudo-labeling 수행
- 추정된 정보와 합성 데이터를 함께 활용하여 forward renderer 학습
실제 영상과 합성 영상의 차이를 줄이기 위해 LoRA (경량 파인튜닝)도 활용했습니다.
왜 우리에게 의미 있을까요?
- 실사 기반 콘텐츠 제작(영상 합성, VFX)에 핵심 기술
- 3D 애셋 없이도 영상 기반 편집이 가능 → 기존 영상에 새로운 물체를 빛 반사 등을 자연스럽게 반영하여 삽입할 수 있는 혁신적인 기능
- 향후 자체 Generative 영상 콘텐츠 제작 AI에 확장 가능성
NVIDIA는 해당 연구를 통해 기업규모를 자랑하듯 막대한 양의 합성 3D 에셋을 이용한 학습용 영상 데이터 제작하였으며 Diffusion, Cross-Attention, LoRA 등 현재 AI 기술의 중추가 되는 핵심 기법들과 최신 렌더링 기술의 집약체를 선보였습니다.
이렇듯 영상 제작과 편집 기술의 발전은 비약적으로 빨라졌으며 그 중심에는 AI가 함께하고 있고 앞으로도 그 영향력은 더 거대해질 것을 저희 AI팀은 확신합니다! |
|
|
📢 AI 기술에 대해 궁금한 점이 있으신 분들은 플랫폼실 AI팀으로 문의주시면
언제든 상담이 가능합니다. 💡 |
|
|
📢 中 콰이쇼우, 영상 생성 AI 모델 ‘클링 2.0’ 출시… “MVL 도입으로 표현력 향상”
콰이쇼우(Kuaishou, 快手)가 15일(현지 시간) ‘Kling AI 2.0’ 행사에서 혁신적인 AI 영상 생성 모델 ‘Kling AI 2.0 Master’를 공식 출시했습니다. 이번 모델은 기존 버전보다 대폭 개선된 성능을 자랑하며, 텍스트나 이미지에서 영상을 생성하는 기능에서 세계 최고 수준의 역량을 보여주고 있는데요. 클링 AI 2.0의 주요 혁신 중 하나는 멀티모델 비주얼 언어(MVL, Multimodel Visual Language)의 도입입니다. 기존에는 텍스트 프롬프트만으로 영상을 생성했지만, MVL은 텍스트와 이미지를 함께 사용해 보다 정확하고 풍부한 표현이 가능하도록 했습니다. 퀀 부사장은 “단순 텍스트만으로는 사람들이 상상하는 것을 완벽하게 묘사하기 어렵다”며 “멀티 엘리먼트 에디터(Multi Elements Editor)를 통해 사용자는 더 직관적이고 정확하게 AI와 소통할 수 있게 됐다”고 설명했습니다. [더보기]
|
|
|
🧠 “AI에게 그림 가르쳐봤습니다” – 데이비드 살레의 실험
요즘 런던에서 화제인 전시가 하나 있습니다. 미국 작가 데이비드 살레(David Salle)의 New Pastorals라는 회화 시리즈인데요, 겉보기엔 그냥 유화처럼 보여도 사실은 AI와 함께 만든 작품들입니다.
원래 디지털 도구에 회의적이던 살레는 몇 년 전부터 AI 이미지 생성기를 직접 훈련시키기 시작했습니다. 워홀의 색감, 호퍼의 공간감, 데 키리코의 구도 같은 유명 화가들의 스타일을 AI에게 입력하고, 본인의 수채화 작품들도 함께 학습시켰습니다. 이렇게 그림의 ‘맛’을 이해하도록 AI를 직접 미대에 입학시킨 셈입니다.
흥미로운 부분은 살레가 AI에게 단순히 그림을 그리라고 명령하는 것이 아니라, AI가 만든 이미지를 보고 거기서 다시 아이디어를 얻는 방식으로 상호작용하고 있다는 것입니다. “AI는 몇 초 만에 결과를 내놓는데, 그걸 사람이 하려면 몇 년은 걸릴지도 몰라요”라는 살레의 말처럼, 속도가 빠른 아이디어 스케치 툴로서의 역할이 컸던 거죠.
이번 New Pastorals는 본인의 과거 작품들을 AI에 학습시킨 뒤, 그 위에 새로운 구성과 붓터치를 더해 완성했습니다. 살레는 AI를 '그저 또 하나의 붓'이라고 명명합니다. 결국 방향은 사람이 잡아야 하고, AI는 도와주는 도구일 뿐이라는 겁니다. 이 실험은 AI가 예술가에게 어떻게 창작의 파트너가 될 수 있는지를 보여주는 좋은 사례가 될 수 있습니다. [더보기]
|
|
|
▶︎ The Green Vest (2025). Photograph: John Behrens/© David Salle / ARS New York, 2025 |
|
|
▶︎ Suspenders (2025). Photograph: John Behrens/© David Salle / ARS New York, 2025 |
|
|
📢 구글, 제미나이에 비디오 모델 '비오 2' 추가…정식 서비스 시작
구글이 ‘제미나이(Gemini)’에 비디오 생성 모델 ‘비오 2(Veo 2)’를 탑재, 정식 서비스를 시작했습니다. 이는 인공지능(AI) 제품 상용화에 집중하고 있는 구글의 최근 전략을 보여주는 움직임에 따른 것인데요. 유료인 ‘제미나이 어드밴스드(Gemini Advanced)’ 구독자는 모델 드롭다운 메뉴에서 비오 2를 선택한 후 프롬프트를 입력해 16대 9 화면비, 720p 해상도의 8초 길이 영상을 생성할 수 있습니다. 모바일 사용자들은 생성된 영상을 ‘공유(Share)’ 버튼을 통해 틱톡이나 유튜브 등에 바로 업로드할 수 있고, 생성된 비디오는 구글의 ‘신스ID(SynthID)’ 기술을 활용해 워터마크가 삽입된 MP4 파일 형태로 다운로드도 가능합니다. [더보기]
|
|
|
|