안녕하세요 :) Cross Planning 본부 이현정입니다.
2025년 11월 4주차 뉴스레터 발송드립니다.📮
<GIANTSTEP News> 빠른 제보는 슬랙 메시지 💌 @XP 사업기획팀 이현정
(📢 매주 목요일 오전까지 접수, 이후 제보는 차주 발행) |
|
|
🦕 GroundingDINO
(플랫폼실 AI팀 기고) |
|
|
🔍 Grounding DINO, 오픈셋 시대의 객체 탐지 모델
최근 Vision-Language 모델의 발전으로, 객체 탐지는 단순히 모델이 정해진 카테고리만 찾는 시대를 넘어, 사용자가 말로 설명한 대상을 그대로 인식하는 ‘오픈셋(Open-set)’ 탐지로 진화하고 있습니다.
Grounding DINO는 간단히 말해, “이미지와 텍스트를 함께 이해하는 DINO 기반의 오픈셋 객체 탐지 모델” 입니다. 기존의 FasterRCNN처럼 카테고리가 고정된 모델과 달리, Grounding DINO는 사용자가 입력한 자연어 문장을 기반으로 이미지 속 대상을 찾아냅니다.
예를 들어,
- “왼쪽에서 두 번째에 있는 사람 찾아줘”
- “손에 커피잔을 들고 있는 사람만 골라줘”
- “바닥에 떨어져 있는 하얀 물체만 표시해줘”
이처럼 학습 카테고리에 없는 대상도, 심지어 상황을 설명해도 탐지가 가능합니다.
이 기술적 전환의 중심에는 세 가지 요소가 있습니다. |
|
|
🧠 1. 이미지 + 언어의 깊은 결합
Grounding DINO는 DINO 구조 위에 언어 인코더(BERT)를 결합하고, 이 둘을 강하게 섞는(fusion) 구조를 채택합니다. 지금까지는 모델이 “이건 사람이다 / 의자다” 정도만 인식했다면, 이제는 “의자에 앉아 있는 사람 중 오른쪽에 있는 사람” 같은 언어적 조건을 정확하게 매칭할 수 있습니다. 이는 복잡한 장면에서의 자동 마스킹, 트래킹 포인트 자동 추출, 카메라 매칭 작업 등에 즉시 응용 가능합니다.
🔍 2. 언어 기반 쿼리 선택(Language-Guided Query Selection)
Grounding DINO의 가장 흥미로운 부분은, 모델이 이미지를 볼 때 텍스트 내용을 기반으로 필요한 영역만 쿼리로 선택한다는 점입니다.
예를 들어 “손에 든 컵”이라는 텍스트를 입력하면,
- 사람 전체를 쿼리로 사용하지 않고 손과 컵 주변의 특징만 q=900개로 추려내어 보다 정교한 추적·탐지가 가능해집니다.
이는 특정 소품, 액세서리, 작은 물체까지 자동으로 인식·분리하기 훨씬 쉬워진다는 의미입니다.
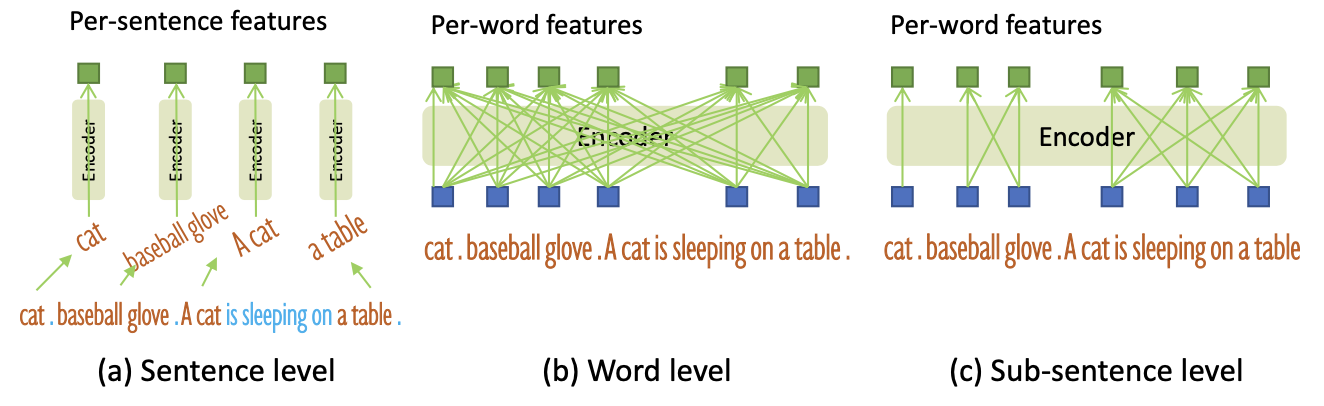
🔄 3. 텍스트를 단어 단위로 쪼개서 이해(Sub-sentence Text Feature)
카테고리가 여러 개 섞인 문장을 넣을 때 생기는 문제—예를 들어 “cat, baseball glove, A cat is sleeping on a table” 같은 prompt—를 해결하기 위해 Grounding DINO는 문장을 단어 단위로 인코딩하고, 서로 관련 없는 단어끼리는 attention mask로 간섭을 막습니다 — (c)Sub-sentence attention 방식. “이 장면에서 ○○만 추출해줘” 같은 명령이 더 자연스럽게 작동하는 이유가 여기에 있습니다.
|
|
|
🚀 왜 중요한 기술일까?
Grounding DINO는 단순히 ‘물건을 찾는 AI’ 이상의 의미가 있습니다.
지금까지 AI는 정해진 메뉴 안에서만 선택할 수 있는 고정형 시스템에 가까웠습니다.
하지만 Grounding DINO는 처음으로,
“사람이 원하는 것을, 말 그대로 그대로 받아들이고 반응하는 AI”를 실현하는 기술이라는 점에서 중요합니다.
|
|
|
📢 AI 기술에 대해 궁금한 점이 있으신 분들은 플랫폼실 AI팀으로 문의주시면
언제든 상담이 가능합니다. 💡 |
|
|
🍌 구글, 이미지 생성 모델 '나노 바나나 프로' 출시…제미나이3 기반
구글이 이미지 생성 AI ‘나노 바나나 프로’를 새롭게 출시했습니다. 이번 모델은 최신 언어 모델인 Gemini 3 기반으로 제작되어 이전 버전보다 더 정교한 이미지와 텍스트를 생성할 수 있습니다. 텍스트 렌더링·편집 기능이 크게 강화되었으며, 카메라 각도, 조명, 심도, 컬러 그레이딩 등 전문가용 세부 제어도 지원합니다. 이미지 해상도는 2K와 4K까지 확장되었고, 웹 검색을 활용한 레시피 카드 제작 등 다양한 활용도 가능해졌습니다. 다만 고품질 이미지를 생성하는 만큼 처리 속도는 느려지고 비용은 상승했습니다. 한 장당 1080p·2K는 0.139달러, 4K는 0.24달러로 책정됐습니다. 최대 6개의 고품질 샷을 적용하거나 이미지 안에 최대 14개 객체를 결합할 수 있으며, 인물 외형도 최대 5명까지 일관되게 유지할 수 있습니다. 구글은 이를 직접 체험할 수 있는 데모 앱도 함께 공개했습니다. [더보기] |
|
|
🧡 맥라렌, 구글 Gemini 3로 F1 팀 운영 전반 혁신
구글과 맥라렌 F1 팀이 파트너십을 한 단계 확장하며, 최신 AI 모델인 Gemini 3를 팀 운영 전반에 본격적으로 도입했습니다. 이번 협업을 통해 맥라렌은 성능 분석, 엔지니어링 아이데이션, 디자인 프로세스 등에서 더 빠르고 효율적인 의사결정을 지원받게 됩니다. 여기에 안드로이드, 픽셀, 크롬, 클라우드 등 구글 생태계도 계속 활용해 팀의 디지털 역량을 강화할 예정입니다.
팬들을 위한 콘텐츠 역시 확대됩니다. 랜도 노리스와 오스카 피아스트리가 등장하는 새로운 디지털 콘텐츠가 공개되며, 라스베이거스 스피어에서는 Gemini를 이용해 맥라렌 F1 머신을 코믹북·8비트 스타일로 변환한 대형 비주얼도 선보입니다. 이번 협업은 레이싱, 차세대 AI, 소비자 기술이 결합된 새로운 시도로, 맥라렌의 혁신 전략을 보여주는 사례로 평가됩니다. [더보기]
- 화제를 불러 모은 파트너십 확장 축하 광고 스피어 송출 영상 [바로가기]
|
|
|
(영상 캡쳐 이미지=google gemini 인스타그램) |
|
|
🔍 디즈니 플러스, AI 생성 영상 도입 검토 중… “시청자가 직접 콘텐츠 제작”
디즈니가 디즈니 플러스에 AI 기반 영상 생성 기능을 도입하는 방안을 검토하고 있습니다. 밥 아이거 CEO는 컨퍼런스콜에서 AI가 시청자에게 직접 짧은 영상을 만들고 소비할 수 있는 새로운 형태의 경험을 제공할 수 있다고 밝혔습니다. 그는 AI가 플랫폼을 더욱 역동적으로 만들고, 이용자에게 창작 기회를 제공하는 중요한 도구가 될 것이라 설명했지만, 구체적인 기능 구현 방식은 공개하지 않았습니다.
한편 디즈니 플러스는 2025년 4분기에 북미에서 150만 명의 신규 가입자를 확보하며 총 5,930만 명의 가입자를 기록했습니다. 디즈니는 최근 요금제를 인상한 바 있으며, 게임·커머스 등으로 플랫폼을 확장할 계획도 언급했습니다. 에픽게임즈와의 협업을 통해 ‘게임과 같은 기능’을 도입할 가능성이 제시됐고, 디즈니 파크·호텔·크루즈 이용과 연계되는 커머스 기회도 강화할 수 있다고 덧붙였습니다. [더보기]
|
|
|
🎮 구글 딥마인드, 제미나이로 게임 AI 혁신…시마2 공개
구글 딥마인드가 차세대 게임 기반 AI 에이전트 ‘시마2(SIMA2)’를 공개했습니다. 시마2는 제미나이 기반으로 구축되어 다양한 3D 가상 세계에서 지시를 이해하고 문제를 해결하도록 설계된 모델로, 기존 버전보다 복잡한 작업 수행 능력이 크게 향상됐습니다. 사용자는 텍스트, 음성, 화면 드로잉 등으로 명령할 수 있으며, 시마2는 게임의 픽셀 정보를 분석해 도구 사용, 탐색, 협력 등의 행동을 학습합니다.
학습에는 노 맨즈 스카이와 고트 시뮬레이터3 등 여러 상업용 게임과 가상 환경이 활용됐으며, 딥마인드는 이를 통해 장기적으로 현실 세계 로봇 기술로 확장하기 위한 기반을 마련하고자 합니다. 시마2는 생성 모델 ‘지니3(Genie3)’와의 결합 실험에서 반복 학습 성능을 보여줬지만, 복잡한 작업에서는 여전히 한계를 드러냈고 인간 수준의 조작 능력에는 미치지 못한다는 평가도 나왔습니다. 딥마인드는 향후 지니3와의 통합을 강화해 시마2의 자율 학습 능력을 발전시킬 계획입니다. [더보기]
|
|
|
|