안녕하세요 :) Cross Planning 본부 이현정입니다.
2025년 9월 2주차 뉴스레터 발송드립니다.📮
<GIANTSTEP News> 빠른 제보는 슬랙 메시지 💌 @XP 사업기획팀 이현정
(📢 매주 목요일 오전까지 접수, 이후 제보는 차주 발행) |
|
|
🦖 DINOv3: 대규모 Self-Supervised Visual Encoder의 현재형
(플랫폼실 AI팀 기고) |
|
|
DINOv3: 대규모 Self-Supervised Visual Encoder의 현재형
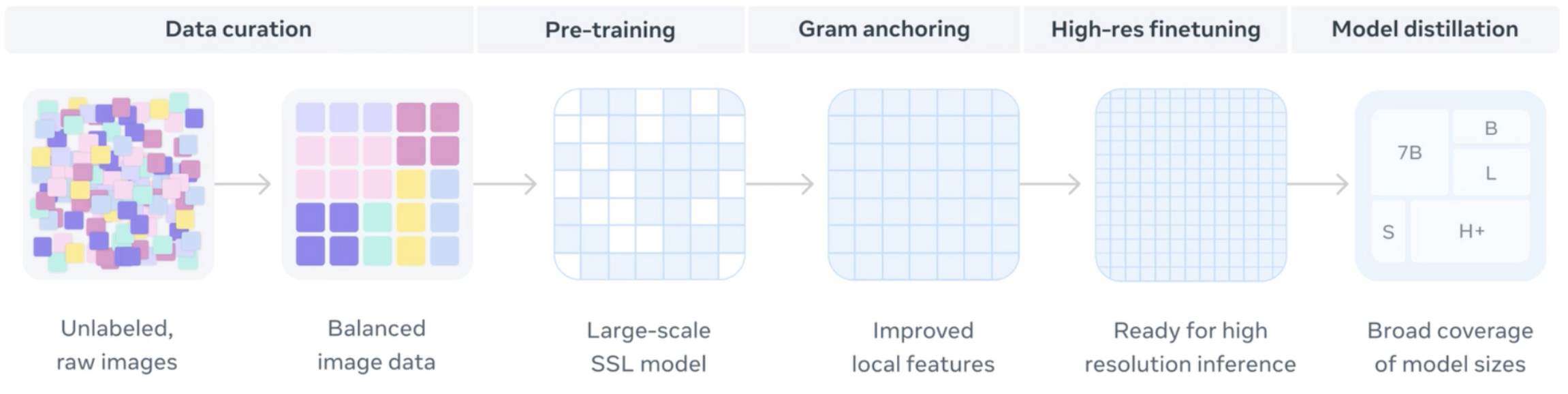
만약 하나의 비전 백본으로 분류·검출·세그멘테이션을 모두 커버하고, 4K 해상도에서도 특징의 일관성을 유지할 수 있다면? 장기 학습에서 무너지던 dense feature를 Gram Anchoring으로 붙잡고, 데이터 스케일로 밀어붙인 모델이 있습니다. 바로 오늘 알아볼 모델 DINOv3 입니다. |
|
|
DINO?
DINO는 2021년 메타에서 발표한 Vision Transformer기반 teacher-student distillation self-supervised learning모델입니다. 2023년에는 CLIP과 같이 weakly-supervised learning 방식과 더욱 정제된 데이터로 1.1B 파라미터에 학습한 DINOv2를 발표하며 더욱 범용성과 정확성을 개선하였습니다. 하지만 SSL은 학습이 길어질 수록 패치 유사도 맵이 퍼지며 segmentation과 같은 dense task에 대해서 성능이 떨어지는 문제가 있었습니다. DINOv3에서는 이를 1. 데이터와 2. Gram Anchoring을 통해 개선하였습니다. |
|
|
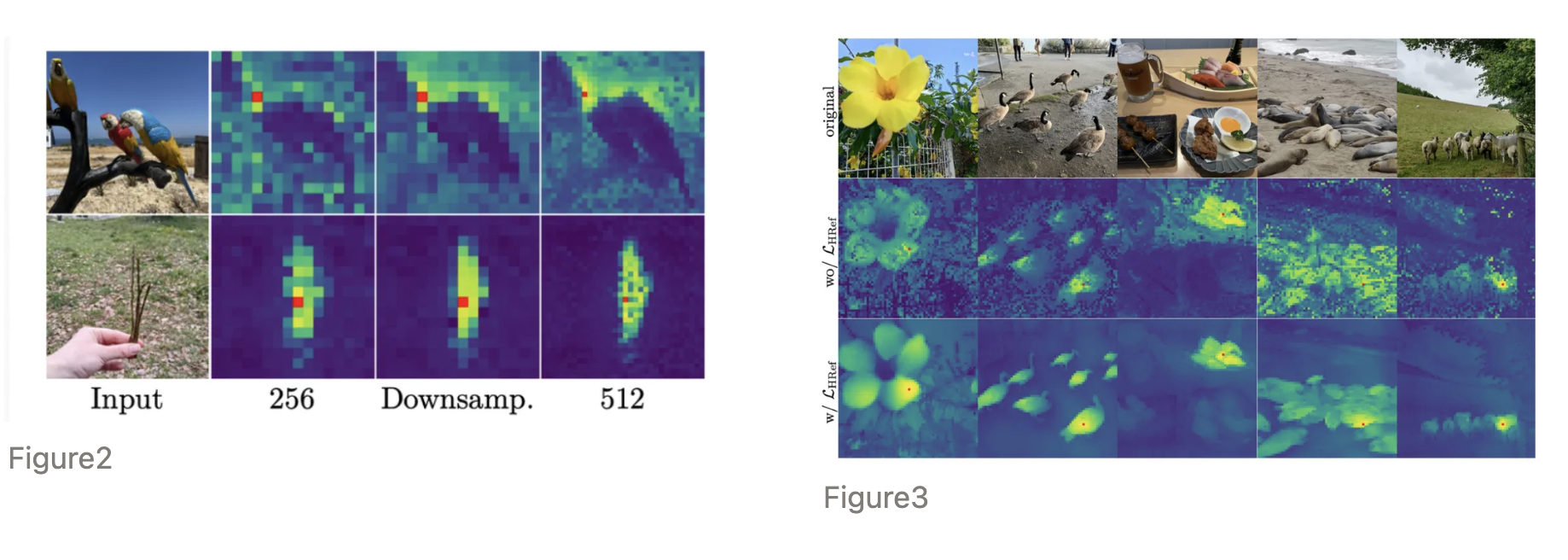
위의 이미지에서 DINOv3가 4K 이미지에 대해서도 semantic한 정보를 잘 유지하는 것을 확인 할 수 있습니다. 이미지는 빨간 + 부분에 대하여 주변 특징정보들의 코사인 유사도를 시각화 한 결과 입니다.
DINOv3: Data
무작정 많은 수의 데이터에 비례하여 모델의 성능이 좋아지는 것은 아니기 때문에 데이터를 잘 수집하고 정제하는것도 중요합니다. DINOv3에서는 아래와 같은 방식으로 약 1.7B 이미지 데이터셋을 구성하였습니다.
Data Collection:
- Instagram 공개 포스트에서 부터 17B의 웹 이미지를 수집
Data Curation:
- DINOv2로 이미지 임베딩을 한 뒤 k-means clustering (Vo et al., 2024) - 5 단계로 (200M, 8M, 800k, 100k and 25k) 군집 한 다음 balanced sampling algorithm을 적용하여 1,689M개의 curated subset을 구성
- Retrieval-based (Oquab et al., 2024) - 수많은 데이터들에서 서로 비슷한 카테고리로 분류될 수 있도록 retrieve하여 downstream task를 커버할 수 있도록함
- 추가적으로 open source data 사용 - ImageNet1K, ImageNet22K, Mapillary Street-level Sequences
DINOv3: Model at scale
Model Parameters
- 이전 모델인 DINOv2의 1.1B 파라미터에서 7B으로 스케일업
Gram Anchoring
- Gram Matrix - 모든 패치의 feature들에 대해서 dot product를 계산한 행렬
- Gram Anchoring - 이전 teacher 모델의 Gram Matrix를 student 모델이 학습 하도록 함
단순한 최적화
- 하이퍼 파라미터를 상수로 고정하며 다운스트림 성능이 오를 때까지 계속
해상도 적응
- 고해상도(최대 4K)에서도 의미 보존되는 특징 지도를 유지하기 위해서 Gram teacher Matrix 에서 인풋 이미지의 2배 해상도를 사용한 다음 2xdown sampling을 하여 feature map을 얻음
- Figure3에서 1K 이미지에 대해서 특징맵이 더 정확하고 smooth한 것을 확인 함
|
|
|
- 배포 준비: 7B 교사 → S/B/L /H+ 학생
- 다시 한 번 teacher-student distillation으로 실사용 크기 모델 제공 각각의 학생 모델도 각 벤치마크에서 높은 성능을 보였습니다.
DINOv3 요약 |
|
|
📢 AI 기술에 대해 궁금한 점이 있으신 분들은 플랫폼실 AI팀으로 문의주시면
언제든 상담이 가능합니다. 💡 |
|
|
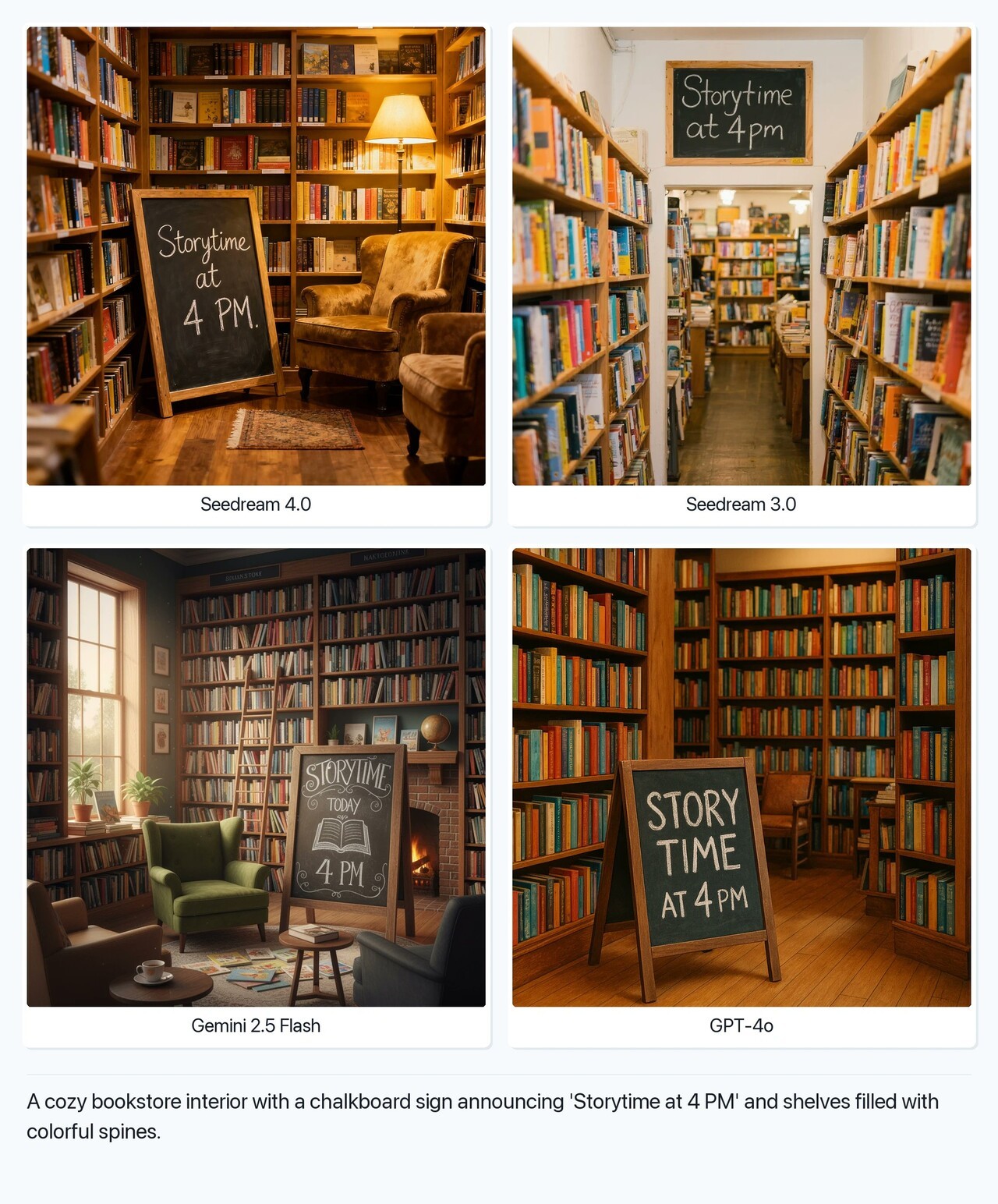
🧠 바이트댄스, '나노 바나나'에 맞설 새로운 AI 이미지 모델 공개
바이트댄스가 차세대 이미지 생성 인공지능 시드림 4.0을 출시하며 구글 딥마인드의 제미나이 2.5 플래시 이미지와 본격 경쟁에 나섰습니다. 시드림 4.0은 텍스트-이미지와 편집 기능을 통합하고 새로운 아키텍처를 적용해 속도를 10배 이상 향상시켰으며, 가격은 1000회 생성당 30달러로 유지했습니다. FAL 플랫폼에서는 1장당 0.03달러에 제공돼 구글 모델보다 저렴합니다. 구글 제미나이 2.5 플래시는 정확성과 일관성으로 호평을 받으며 현재 벤치마크 1위를 차지하고 있고, 시드림 3.0은 LM아레나에서 상위권에 올라 있습니다. 새 버전인 시드림 4.0은 중국 내 AI 앱 지멍, 더우바오와 기업용 클라우드 서비스 볼케이노 엔진을 통해 제공됩니다. [더보기]
|
|
|
🎬 오픈AI, 소라로 만든 장편 애니메이션 ‘크리터즈’로 칸 영화제 도전
오픈AI가 자체 AI 도구로 제작했던 단편 애니메이션 〈Critterz〉를 장편 영화로 확장하며 할리우드 진출에 나섭니다. 월스트리트저널에 따르면 이번 프로젝트는 약 3천만 달러 규모로 진행되며, 2026년 5월 칸 영화제에서의 프리미어를 목표로 하고 있습니다. 일반적으로 애니메이션 영화 제작에는 3년 이상이 걸리고 예산도 수억 달러에 달하지만, 오픈AI는 1년이 채 안 되는 기간과 상대적으로 적은 예산으로 완성하겠다는 계획을 내세웠습니다. 이를 통해 생성형 AI가 영화 제작 방식에 변화를 가져올 수 있음을 보여주려는 시도입니다. 영화에는 실제 배우들이 캐릭터 목소리를 맡고, 아티스트가 그린 스케치를 GPT-5 등 AI 모델에 입력해 영상화하는 방식이 활용됩니다. 각본은 Paddington in Peru 작가진이 담당합니다. 제작은 런던의 Vertigo Films와 LA의 Native Foreign이 맡으며, 약 30명이 참여할 예정입니다. 오픈AI는 칸 영화제 데뷔 이후 전 세계 극장 개봉을 추진하고 있으나, 배급사는 아직 확정되지 않았습니다. [더보기]
|
|
|
📱 랄프 로렌, AI 스타일링 서비스 ‘Ask Ralph’ 론칭
랄프 로렌이 인공지능 기반 쇼핑 서비스 ‘Ask Ralph’를 론칭했습니다. 25년 전 웹 서비스로 처음 선보였던 이름을 AI로 재해석해, 개인 맞춤형 스타일링과 즉시 구매가 가능한 경험을 제공합니다. 1년간 개발된 AI는 브랜드 아카이브와 철학을 학습해 상황별 쇼핑 옵션을 제안하며, 테스트 단계부터 실용성과 상업성에 초점을 맞췄습니다. ‘Ask Ralph’는 브랜드 최초의 소비자 대상 AI 도구로, 향후 음성 인식이나 플랫폼 확장도 계획 중입니다. 랄프 로렌은 속도를 좇기보다 정체성을 지키며 점진적으로 AI를 접목해 나가겠다고 밝혔습니다. [더보기] |
|
|
🌟 3천 대 드론이 수놓은 성 베드로 광장, 인류 연대의 메시지
이탈리아 로마 바티칸 성 베드로 광장에서 열린 ‘Grace for the World’ 공연에 8만 명이 넘는 관객이 모였습니다. 세계 형제애 회의 2025의 마지막 행사로 마련된 이번 무대에는 안드레아 보첼리, 퍼렐 윌리엄스, 존 레전드, 제니퍼 허드슨, 카롤 G 등 세계적인 아티스트들이 참여했습니다. 퍼렐 윌리엄스는 개막 연설에서 “진정한 연민과 은총은 형제애에서 시작된다”며 종교와 문화를 넘어 인류가 하나 되는 메시지를 전했습니다. 또 공연 직후에는 3천 대가 넘는 드론이 성 베드로 대성당 상공을 수놓으며 프란치스코 교황의 얼굴, 성모 마리아, 미켈란젤로의 ‘천지창조’ 등을 형상화해 큰 화제를 모았는데요. 이번 드론쇼는 일론 머스크의 동생 킴벌 머스크가 운영하는 ‘Nova Sky Stories’가 연출했습니다. 이번 행사는 음악과 예술, 종교적 상징이 결합해 분열과 양극화의 시대 속에서도 형제애라는 보편적 가치를 재확인하는 장이 되었습니다. [더보기] |
|
|
|