OpenAI의 *CLIP(*Contrastive Language-Image Pre-training) 모델은 텍스트와 이미지를 연결하는 강력한 멀티모달 AI로 유명합니다. 이러한 성능 덕분에 많은 AI 모델에서 입력 자료를 받아들이는 인코더(encoder)로서의 역할로 사용되고 있죠. 하지만, 물체의 색상, 수량, 구조, 방향성 등을 세밀하게 구별하는 능력에는 한계가 있습니다. 그 이유는 학습 데이터의 한정된 다양성과 대비 학습(contrastive learning)의 특성 때문입니다.
최근 발표된 논문 "Diffusion Feedback Helps CLIP See Better" 는 CLIP이 놓치는 디테일을 보완하는 혁신적인 방법을 제안합니다. 바로 Diffusion Model을 활용한 생성적 피드백(generative feedback) 으로CLIP의 성능을 개선하는 DIVA(DIffusion model as a Visual Assistant) 입니다!
DIVA: Diffusion이 CLIP의 비주얼 어시스턴트가 된다!
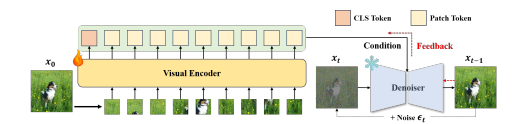
DIVA라는 새로운 접근법을 통해, CLIP의 인식 능력을 강화하는 Diffusion Feedback 메커니즘을 설계했습니다.
CLIP이 이미지에서 추출한 시각적 피처를 Diffusion Model이 추가 학습
Diffusion이 생성한 피드백을 통해 CLIP이 더 정교한 디테일을 학습
모델의 무게는 그대로 유지하면서 성능은 향상!
실험 결과: 성능은 얼마나 좋아졌을까?
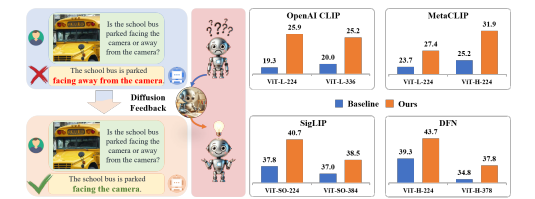
DIVA는 text-image 계열 AI의 성능을 평가하는 MMVP-VLM 벤치마크 테스트에서 기존 CLIP 대비 3~7% 성능 향상을 보이며,
특히 OpenAI ViT-L-14, MetaCLIP ViT-H-14 등의 모델에서도 성능 개선이 확인되었습니다.
이 연구가 기여한 것
기존 연구들은 CLIP의 성능을 높이기 위해 더 큰 모델을 학습하는 접근을 사용하거나 CLIP을 통해 Diffusion과 같은 생성형 모델의 성능을 개선하는 시도를 해왔습니다. 그러나 DIVA는 반대로 기존 모델을 유지하면서도 가볍게 개선하는 방법을 제시했습니다.
그러한만큼 이 연구는 ICLR 2025에 선정되었으며, 향후 CLIP뿐만 아니라 다양한 멀티모달 AI 모델에서도 활용될 가능성이 큽니다. 어쩌면 결과로서의 multi-modality가 아닌 과정으로서의 상호보완적 multi-modality에 대한 새로운 접근법을 제시한 것일 수도 있지 않을까 하는 생각도 합니다.
👉 Diffusion Feedback, AI의 새로운 패러다임이 될 수 있을까요? 앞으로의 연구를 기대해 봅시다!
LG AI연구원이 자체 개발한 국내 최초 추론 인공지능(AI)인 ‘엑사원 딥’(EXAONE Deep)을 오픈소스로 공개하며 ‘에이전틱(Agentic) AI’ 시장 경쟁 대열에 합류했습니다. 에이전틱 AI는 스스로 가설을 세우고 이를 검증하기 위한 추론을 진행하는 과정을 통해 자율적으로 의사결정을 할 수 있는 능동적인 AI인데요. 현재 추론 AI 시장을 중국 딥시크, 미국 오픈AI가 주도하고 있다는 점에서 국내 AI 경쟁력을 보여준 사례로 주목됩니다. 엑사원 딥-32B는 오픈소스 공개와 함께 미국의 비영리 AI 연구기관인 에포크 AI가 선정하는 주목할 만한 AI 모델 리스트에 등재되며 기술 경쟁력을 인정받았다고 하네요. [더보기]
AI가 댓글 쓴다…인스타그램, 신기능 테스트 중
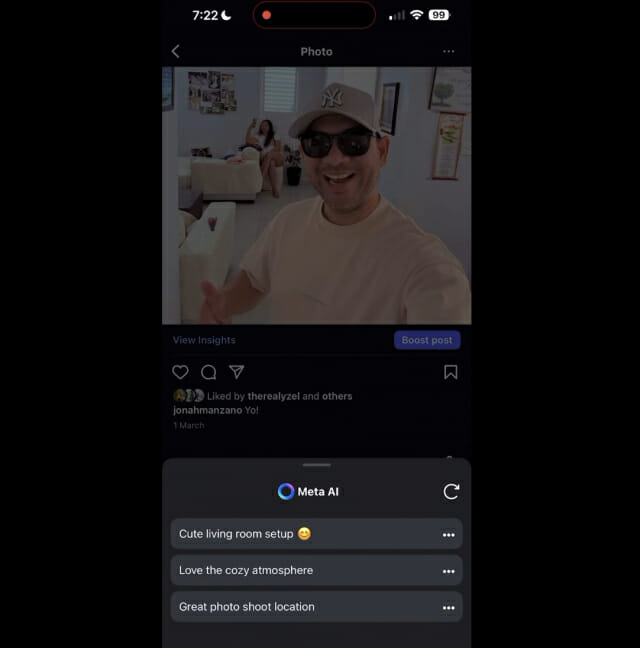
메타가 인스타그램에서 AI를 활용한 댓글 생성 기능을 테스트 중인 것이 포착됐습니다. 소셜 미디어 기능을 자주 테스트하는 X(트위터) 사용자인 요나 만자노(Jonah Manzano)가 인스타그램에서 '메타 AI와 함께 쓰기'라는 새로운 기능을 발견했는데, 이것이 바로 AI가 게시물에 대한 댓글을 제안하는 기능이었다고 하는데요. 사용자는 연필 아이콘을 통해 이 기능에 접근할 수 있으며, AI는 사진을 분석한 후 3가지 댓글을 제안합니다. 예를 들어, 거실에서 웃고 있는 사람의 사진에는 '귀여운 거실 세팅', '아늑한 분위기가 마음에 든다', '훌륭한 사진 촬영 장소'라는 댓글이 제안됩니다. 마음에 들지 않으면 새로고침을 통해 다른 제안을 받을 수 있다고 하네요. 메타 대변인은 "우리는 메타 AI를 앱 전반에서 사용할 수 있도록 정기적으로 테스트하고 있다"고 밝혔습니다. [더보기]
국립중앙박물관, 3D 전시공간 '공간_사이' 선봬
국립중앙박물관이 상설전시관 감각전시실 ‘공간_사이’를 새롭게 조성하고 한국의 범종 소리를 주제로 다감각 체험 전시를 선보입니다. ‘공간_사이’는 한국 범종 소리의 원리를 여러 감각을 통해 경험해 보는 공간으로, 한국 범종을 대표하는 국보 '성덕대왕신종' 소리의 특징인 맥놀이(소리의 강약이 반복되며 길고 은은하게 이어지는 현상)를 시각·청각·촉각으로 느껴볼 수 있습니다. 공간 중앙에 폭 4m, 높이 4m의 대형 LED 화면 구조체를 배치하여 영상 안에서 '성덕대왕신종'의 거대한 존재감을 구현했으며, 영상에는 한국 범종 소리의 원리를 시각화해서 보여주는 한편 실제 '성덕대왕신종'의 종소리에 기반한 미디어아트를 선보인다고 합니다. [더보기]
캐릭터 AI '크랙' 독립 출격…"내 최애와 양방향 소통, 현실 된다"
누구든 좋아하는 캐릭터와 직접 대화할 수 있는 인공지능(AI) 챗봇 서비스 '크랙'이 출시됩니다. 기존에는 '캐릭터 챗'이라는 채팅 기능 중 하나였으나 유저들의 높은 호응을 바탕으로 단독 출시하게 된 것인데요. 크랙 내에서는 '엘프 여왕 메이브'나 '연애고수 선배'처럼 각기 다른 세계관과 성격을 지닌 캐릭터들이 존재하며 유저는 이들과의 대화를 통해 판타지 RPG부터 학원 시뮬레이션까지 다양한 가상 스토리를 직접 체험할 수 있습니다. 유저 취향 기반 캐릭터 추천 기능을 통해 수많은 캐릭터 중에서도 선호하는 스타일을 손쉽게 찾을 수 있으며, 별도 코딩이나 복잡한 설정 없이 텍스트 기반으로 캐릭터를 제작하여 플랫폼 내에서 공유할 수도 있다고 하네요. [더보기]